
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- mifare
- sLLM
- 파이썬
- team_project
- ML
- pandas
- lightsail
- djangorestframework
- django
- Github
- ollama
- Jupyterlab
- EC2
- ai 캠프
- 정치기 필기
- finpilot
- aws
- chromeextention
- 머신러닝
- mysql
- ai_캠프
- 오블완
- seaborn
- 로컬 런타임
- 티스토리챌린지
- pytorch
- ai캠프
- streamlit
- Python
- conda
- Today
- Total
greatsangho의 이야기
캠프54일차 - LLM 파인튜닝 개념과 기본 준비 본문
LLM의 기본 개념
- 텍스트 생성, 요약, 번역, 질문 응답
- GPT, BERT : 트랜스포머 계열
- 트랜스포머 아키텍처 : 2007년 논문(Attention is All You Need)
- RNN, LSTM, GRU 보다 효율적
- 병렬화에 유리
- 인코더
- 입력 문장에서 패턴 추출, 이해
- BERT
- 디코더
- 인코더가 추출한 문장을 바탕으로 새로운 문장을 생성
- GPT
- 어텐션
- 마스크를 사용해서 집중해야 될 문장을 표시 1 1 1 0 0 0
LLM 구성 요소
- 임배딩 레이어 : 단어를 벡터로 변환
- 셀프 어텐션 : 트랜스포머의 핵심 매커니즘
- 포지션 인코딩 : 순서 정보를 추가(앵글... 사인, 코사인)
- 피드 포워드 네트워크 : 각 토큰을 독립적으로 처리하는 신경망(완전연결)
- 레이어 정규화, 드랍아웃 : 과적합 방지
LLM 학습
- 사전학습(Pre-trainning) : 모델을 로드
- 파인 튜닝(Fine-tuning) : 사용자가 추가한 데이터를 추가로 학습, 대규모 학습이 어렵고 비용 절감을 위해 시행
파인 튜닝의 절차 : 영화 리뷰(긍정,부정)
- 파인튜닝을 할 데이터를 확보
- 전처리
- 크롤링을 통해 수집한 데이터 태그 삭제
- 영문이면 소문자로 변환
- 특수문자 및 기타 등등 -> 정규화를 통해
- 토큰의 크기를 제한(파인튜닝 대상 문장의 80% 이상을 포함하는 길이) - precentile(data, 95)
- 시각화
- 모델을 선택 (GPT, BERT) 및 로드
- 모델 맞게 설계된 토크나이져
- 전처리한 데이터를 토크나이져를 통해 토큰화
- 모델
- 학습 파라미터를 설정
- 저장 경로, 학습률, 에포크 수, 등..
- 평가 지표 정의(정확도)
- 함수화
- Trainer 초기화
- Trainer를 이용해서 모델 파인튜닝, trainer.train()
- 학습 후 평가
- trainer.evaluate()
- 추론
- 평가용 문장
- 토크나이져로 토큰화 -- input
- 모델에 적용 model(**inputs)
- 결과를 평가(torch.argmax)
분류
- kogpt2 모델을 이용 영화 데이터 긍정/부정 이진분류
import urllib
import pandas as pd
import re
# 데이터 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")
# 데이터 불러오기
train_data = pd.read_table('ratings_train.txt')
test_data = pd.read_table('ratings_test.txt')
# 결측치 제거
train_data.dropna(inplace=True)
test_data.dropna(inplace=True)
# 한글만 추출 (정규식 사용)
train_data['document'] = train_data['document'].apply(lambda x: re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣\s]', ' ', str(x)))
test_data['document'] = test_data['document'].apply(lambda x: re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣\s]', ' ', str(x)))
# 중복 제거
train_data.drop_duplicates(subset=['document'], inplace=True)
test_data.drop_duplicates(subset=['document'], inplace=True)
# 인덱스 리셋
train_data.reset_index(drop=True, inplace=True)
test_data.reset_index(drop=True, inplace=True)
print(f'전처리 후 훈련 데이터 크기: {train_data.shape}')
print(f'전처리 후 테스트 데이터 크기: {test_data.shape}')먼저 영화 리뷰 데이터를 불러오고 데이터 전처리를 진행한다.
불러온 데이터에서 결측치 제거, 한글에 해당하는 부분만 남기기, 중복 제거 및 인덱스 리셋을 시행한다.

# 적절한 토큰의 길이
print(train_data['document'].map(lambda x: len(x.split())).describe())
# 토큰의 길이는 95% 구간을 선택
import numpy as np
max_token_len = np.percentile(train_data['document'].apply(lambda x : len(x.split())), 95)
# max_token_len = np.percentile(train_data['document'].map(lambda x : len(x.split())), 95)
print(f'max_token_len : {max_token_len}')
# 시각화
# train_data['document'].map(lambda x: len(x.split())).hist(bins=50)
train_data['document'].apply(lambda x: len(x.split())).hist(bins=50)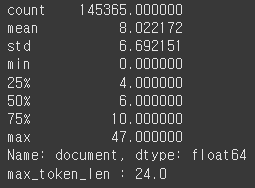

전처리한 데이터의 특성을 알아본다. 공백으로 구분하여 단어의 개수를 센다. 전체 길이 분포에서 95%에 해당하는 길이는 24이다. 히스토그램으로 보면 다음과 같은 분포를 보인다.
from transformers import PreTrainedTokenizerFast, GPT2ForSequenceClassification
import torch
# 토크나이저 로드
tokenizer = PreTrainedTokenizerFast.from_pretrained('skt/kogpt2-base-v2', bos_token='</s>', eos_token='</s>', pad_token='<pad>')
# KoGPT2 모델 로드 (이진 분류를 위한 GPT2ForSequenceClassification 사용)
model = GPT2ForSequenceClassification.from_pretrained('skt/kogpt2-base-v2', num_labels=2)
# GPU 사용 설정 (가능한 경우)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)데이터셋을 토큰화 하기 위해 토크나이저와 모델을 로드한다.
def tokenize_and_encode(data, tokenizer):
return tokenizer(
data['document'].tolist(),
padding=True,
truncation=True,
return_tensors='pt',
max_length=int(max_token_len)
)
train_encodings = tokenize_and_encode(train_data, tokenizer)
test_encodings = tokenize_and_encode(test_data, tokenizer)
train_labels = torch.tensor(train_data['label'].values)
test_labels = torch.tensor(test_data['label'].values)토크나이져로 인코딩을 위해 tokenizer를 함수로 선언한다. 리뷰에 해당하는 부분과 정답 labels을 분리하여 리뷰에 해당하는 부분을 인코딩한다.
from torch.utils.data import DataLoader, TensorDataset
train_dataset = TensorDataset(train_encodings['input_ids'], train_encodings['attention_mask'], train_labels)
test_dataset = TensorDataset(test_encodings['input_ids'], test_encodings['attention_mask'], test_labels)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32)train과 test 데이터를 집어넣을 dataset을 만들어 준다.
from transformers import AdamW
from tqdm import tqdm
optimizer = AdamW(model.parameters(), lr=5e-5)
# 학습 루프 정의
for epoch in range(1): # 에포크 수 설정
model.train()
for batch in tqdm(train_loader):
input_ids, attention_mask, labels = [b.to(device) for b in batch]
optimizer.zero_grad()
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1} completed.')모델을 적용한다.

from sklearn.metrics import accuracy_score
model.eval()
predictions, true_labels = [], []
with torch.no_grad():
for batch in test_loader:
input_ids, attention_mask, labels = [b.to(device) for b in batch]
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
predictions.extend(torch.argmax(logits, dim=-1).cpu().numpy())
true_labels.extend(labels.cpu().numpy())
accuracy = accuracy_score(true_labels, predictions)
print(f'Test Accuracy: {accuracy:.4f}')학습을 평가한다.

# skt 모델이 생성형 : 분류할 때는
# 생성형 모델 파인튜닝
# 대화형식
# 문자요약
# 감정분석 ***
# 번역
# 스타일 변환(공손한 말투, 예언자 스타일)
# 자연어 생성
# 코드리뷰
추론
QA 파인튜닝
1. 토크나이저 로드
from transformers import PreTrainedTokenizerFast
tokenizer = PreTrainedTokenizerFast.from_pretrained(model_name,
bos_token='</s>', eos_token='</s>', unk_token='<unk>',
pad_token='<pad>', mask_token='<mask>')Hugging Face의 PreTrainedTokenizerFast를 사용하여 토크나이저를 로드한다.
bos_token : 문작의 시작
eos_token : 문장의 끝
unk_token : 알 수 없는 토큰
pad_token : 패딩 토큰
mask_token : 마스크 토큰
을 설정한다.
2. 데이터셋 클래스 정의
class QADataSet(Dataset):
def __init__(self,tokenizer,question,answer,max_length = 128):
...QA DataSet클래스를 정의한다. 이는 파이토치의 Dataset 클래스를 상속 받는다.
__init__():
input_encodings = tokenizer(input_text, padding='max_length', add_special_tokens=True, truncation=True, max_length=max_length)
질문과 답변 데이터를 받아서 각 문장을 토큰화하고, 이를 input_ids, labels, attention_mask로 저장한다.
input_text는 "질문: {질문} 답변:" 형식으로 만들어지고, target_text는 실제 답변이다.
tokenizer() 메서드를 사용해 텍스트를 토큰화하고, 최대 길이를 설정하며 패딩을 적용한다.
__len__(): 데이터셋의 길이 반환
return len(self.question)
__getitem__():
question = self.question[idx]
인덱스에 해당하는 질문과 답변 데이터를 반환, 반환할 때는 PyTorch 텐서로 변환하여 모델에 입력할 수 있도록 설정
3. 데이터 준비
questions = ['안녕하세요 오늘날씨가 어때요?', '단위프로젝트 주제는 뭔가요?', '프로젝트 목표는 뭔가요?']
answers = ['안녕하세요 오늘 날씨는 좋아요', '내외부문서를 활용한 QA 시스템 입니다.', ...]
dataset = QADataSet(tokenizer, question=questions, answer=answers)
dataloader = DataLoader(dataset, batch_size=2)예시 질문과 답변 데이터를 준비하고 이를 QADataSet 클래스를 통해 데이터셋으로 변환
DataLoader: 학습 시 배치 단위로 데이터를 처리하기 위해 PyTorch의 DataLoader를 사용, 이진 분류이므로 2로 설정
4. 모델 로드 및 설정
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained(model_name)
5. 옵티마이저 및 스케줄러 설정
# 옵티마이저(AdamW : 가중치 감쇠를 적용한 Adam)
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=1e-5)
# 스케줄러(학습률을 점진적으로 줄임)
from transformers import get_linear_schedule_with_warmup
epochs = 10
total_steps = len(dataloader) * epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
6. 모델 학습
model.train()
from tqdm import tqdm
iterator = tqdm(range(epochs))
for epoch in iterator:
for batch in dataloader:
optimizer.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
scheduler.step()
iterator.set_description(f'Epoch {epoch+1} loss :{loss.item()}')model.train() 으로 모델 학습모드로 전환
각 배치마다 옵티마이저의 그래디언트를 초기화 (optimizer.zero_grad())
모델에 입력 데이터를 넣어 출력(outputs)을 얻고, 그 안에서 손실(loss) 값을 추출
손실에 대해 역전파(loss.backward())를 수행하여 그래디언트를 계산한 후 옵티마이저가 파라미터를 업데이트 (optimizer.step())
스케줄러를 통해 학습률을 업데이트 (scheduler.step())
7. 답변 생성
question = '어제 날씨는 어떤가요?'
input_text = f'질문:{question} 답변:'
input_ids = tokenizer.encode(input_text,add_special_tokens=True,
truncation=True, max_length=128,return_tensors='pt').to(device)모델 학습 형식에 맞춘 질문 텍스트 준비
input_ids에서 input_text 토큰화
tokenizer.encode(): transformers 라이브러리의 토크나이저를 사용하여 input_text를 토큰화
add_special_tokens=True: 모델이 요구하는 특별 토큰 (예: 문장의 시작/끝 토큰)을 추가
truncation=True: 입력 텍스트가 너무 길 경우, 최대 길이를 초과하지 않도록 잘라내기
max_length=128: 최대 128개의 토큰까지만 허용
return_tensors='pt': PyTorch 텐서 형식으로 반환
8. 생성된 답변 디코딩 및 출력
with torch.no_grad():
gen_ids = model.generate(input_ids,
max_length=128,
repetition_penalty=2.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
generated = tokenizer.decode(gen_ids[0])
print(generated)torch.no_grad(): 이 블록 안에서는 그래디언트 계산을 하지 않겠다는 의미, 즉, 모델의 추론(inference) 단계에서만 사용되며, 메모리 사용량을 줄이고 성능을 향상
model.generate(): GPT-2 기반 모델에서 텍스트 생성을 수행하는 함수
input_ids: 위에서 토큰화한 입력 데이터를 모델에 전달
max_length=128: 생성할 텍스트의 최대 길이를 128 토큰으로 제한
repetition_penalty=2.0: 반복되는 단어나 구문이 나오지 않도록 패널티를 적용. 값이 클수록 반복이 덜 발생.
pad_token_id, eos_token_id, bos_token_id: 각각 패딩 토큰, 문장 끝 토큰, 문장 시작 토큰의 ID를 설정. 모델이 언제 문장을 끝내야 할지 알 수 있도록 도와줌
gen_ids: model.generate() 함수는 여러 개의 시퀀스를 반환 가능. 여기서는 첫 번째 시퀀스만 사용.
tokenizer.decode(): 생성된 토큰 ID들을 다시 사람이 읽을 수 있는 자연어로 변환
- RAG(retriver- augmented generation) : 검색기반 생성 모델
- QA 특화
- NLP : 자연어 처리 + 검색 + 생성
- 질문과 과련된 정보를 검색
- 검색한 내용을 Faiss, Chroma 벡터화
- 검색된 정보를 기반으로 답을 생성
- retriver 구현(검색기)
- generation 생성기
- 모델에 연결
retriver 구현(검색기)
!pip install -q langchain_openai
!pip install -U langchain-community
import os
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from langchain_community.document_loaders import TextLoader, PyPDFLoader,WebBaseLoader
import bs41. 웹 데이터 로드 : 날씨 정보 불러오기
url1 = 'https://korean.visitseoul.net/weather'
url2 = 'https://www.accuweather.com/ko/kr/seoul/226081/daily-weather-forecast/226081'
loader = WebBaseLoader(web_paths=(url1, url2))
documents = loader.load()
2. Chroma 벡터 데이터베이스 구축
persist_directory = 'db2'
embedding_model = OpenAIEmbeddings()
vectordb = Chroma.from_documents(
documents,
embedding=embedding_model,
persist_directory=persist_directory
)persist_directory='db2': 벡터 데이터베이스를 로컬 디렉토리에 저장
OpenAIEmbeddings(): 텍스트를 벡터로 변환하는 임베딩 모델
3. Retriever 설정
retriever = vectordb.as_retriever(search_type='similarity', search_kwargs={'k': 1})retriever: 벡터 데이터베이스에서 관련 문서를 찾기 위한 검색 도구
search_type='similarity': 유사도 기반 검색
search_kwargs={'k': 1}: 가장 유사한 한 개의 문서를 반환
4. 질문에 대한 관련 문서 검색
question = '어제 날시는 어떤가요?'
search_result = retriever.get_relevant_documents(question)get_relevant_documents(): 질문과 가장 관련성이 높은 문서를 검색
5. 한글만 추출하기
import re
find_context = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣\\s]', ' ', search_result[0].page_content)
6. LLM 모델에 적용할 입력 생성
input_text = f'{find_context} 문장을 참고해서 {question} 질문 에 답하시오'
input_ids = tokenizer.encode(input_text, add_special_tokens=True,
truncation=True, max_length=128, return_tensors='pt').to(device)
7. 답변 생성하기
with torch.no_grad():
gen_ids = model.generate(input_ids,
max_length=256,
repetition_penalty=2.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
generated = tokenizer.decode(gen_ids[0])
print(generated)
최신 날씨 정보를 불러와 출력할 수 있다.
'프로그래밍 > SK AI 캠프' 카테고리의 다른 글
| 캠프56일차 - 파인튜닝된 LLM 모델의 성능 평가 방법 (1) | 2024.11.14 |
|---|---|
| 캠프55일차 - PEFT, LoRA 등 다양한 파인튜닝 기법에 대한 심화 학습 (0) | 2024.11.13 |
| 캠프53일차 - 프롬프트 엔지니어링 응용 (Chain of Thought(CoT), Tree of Thought(ToT), Automatic Prompt Engineer(APE)) (8) | 2024.11.11 |
| DACON 대회 출전 - 2024 생명연구자원 AI활용 경진대회 : 인공지능 활용 부문 (0) | 2024.11.10 |
| 윈도우 DirectX12와 WSL을 이용한 모든 GPU에서 tensorflow와 pytorch 사용하기 (1) | 2024.11.09 |



