
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 로컬 런타임
- Github
- pytorch
- 정치기 필기
- mysql
- aws
- 티스토리챌린지
- django
- EC2
- djangorestframework
- pandas
- Python
- finpilot
- conda
- ai_캠프
- ollama
- 파이썬
- 오블완
- sLLM
- streamlit
- lightsail
- mifare
- ai 캠프
- chromeextention
- Jupyterlab
- seaborn
- 머신러닝
- ai캠프
- ML
- team_project
- Today
- Total
greatsangho의 이야기
캠프53일차 - 프롬프트 엔지니어링 응용 (Chain of Thought(CoT), Tree of Thought(ToT), Automatic Prompt Engineer(APE)) 본문
캠프53일차 - 프롬프트 엔지니어링 응용 (Chain of Thought(CoT), Tree of Thought(ToT), Automatic Prompt Engineer(APE))
greatsangho 2024. 11. 11. 19:14- 프롬프트 형식
- 질문
- 지시
- 문답 형식(한가지만)
- 위와 같은 형식을... 제로샷 프롬프트
제로샷(Zero-shot): 예시 없이 명령만으로 작업을 수행하도록 하는 방식
- few shot 프롬프팅
- <질문>
- <답변>
- <질문>
- <답변>
- <등등>
- 멋지다 // 긍정
- 나빠! // 부정
- 최악의 공연이다 //
// 대신 공백이나 : 등 사용 가능함
퓨샷(Few-shot): 몇 가지 예시를 제공하여 AI가 더 나은 결과를 도출하도록 돕는 방식
Colab 기준 설치
!pip install -q langchain
!pip install -q langchain-openai
!pip install -q langchain-community
!pip install -q pypdf
!pip install -q chromadb
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate# prompt
template = '''질문: {question}
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
# 하늘은 이라고만 했을 경우와, 아래와 같이 입력했을 경우를 비교
input_prompt = prompt.format_prompt(question='문장을 완성해 줘 \n\n 하늘은')
output = model(input_prompt)
print(output.content)제로 샷은 다음과 같이 명령만으로 작업을 수행한다.
# prompt
template = '''
멋지다 : 긍정
나빠! : 부정
그 영화는 굉장했어 : 긍정
얼마나 끔찍한 공연인가? :
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)퓨샷은 다음과 같이 몇가지 예시를 주어 결과를 도출한다.
- 프롬프트는 부정확한 표현 피해
- 하지 말아야 할 것 보다는 해야 하는 것에 초점을 둔다.
OpenAI 프롬프트 엔지니어링에 대한 설명
요약하면,
1. 최신 모델을 사용할수록 성능이 좋음
2. 프롬프트를 명확히 구조화한다. 맥락과 지시사항을 구분자를 통해 분리하기
3. 구체적이고 상세하게 작성하기
4. 출력 형식 예시를 제공하기
5. 제로샷에서 시작하고 퓨삿으로 확장하여 fine-tuning
6. 모호한 설명 피하기
7. 명확한 지시 제공, 하지 말아야 할 것보다 무엇을 해야 하는지 지시하기
8. 코드 생성 시 python의 import, SQL의 SELECT 같은 패턴 키워드를 사용해 유도
9. 파라미터 현명하게 사용하기. temperature(출력의 무작위성 제어)와 max_tokens(생성할 토큰 수 제한)을 적절히 조정
으로 정리할 수 있다.
프롬프트는
- 문장 요약
- 정보 추출
- 질의응답
- 텍스트 분류
- 대화
- 코드 생성
- 추론
에 사용할 수 있다.
# 추론
template = '''
주어진 수 중에서 홀수를 모두 더해서 짝수를 만들어 줘 : 10 25 14 25 26 33 25 27 28 35
문제를 단계적으로 해결해봐. 먼저 주어진 수 중에서 홀수를 찾아낸 뒤, 그것들을 합해서 결과가 홀수인지 짝수인지 판별해 줘
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-4o-mini') # gpt-3.5-turbo
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)
# 출력 결과
'''
주어진 수: 10, 25, 14, 25, 26, 33, 25, 27, 28, 35
1. **홀수 찾기**:
- 25 (홀수)
- 25 (홀수)
- 33 (홀수)
- 25 (홀수)
- 27 (홀수)
- 35 (홀수)
따라서, 홀수 목록: 25, 25, 33, 25, 27, 35
2. **홀수 합산**:
\[
25 + 25 + 33 + 25 + 27 + 35 = 170
\]
3. **결과 판별**:
- 170은 짝수입니다.
결론적으로, 주어진 수 중에서 홀수를 모두 더한 결과는 170이며, 이는 짝수입니다.
'''문제를 단계적으로 해결해 보라는 것이 zero-shot CoT에 해당하며 더 나은 결과를 얻을 수 있다.

https://www.promptingguide.ai/techniques/cot
Chain-of-Thought Prompting – Nextra
A Comprehensive Overview of Prompt Engineering
www.promptingguide.ai
Prompt Engineering 에 대한 자세한 설명은 다음 링크를 통해 확인할 수 있다.
Chain of Thought
Chain of Thought (CoT)는 대규모 언어 모델(LLM)이 복잡한 문제를 해결할 때 단계별 추론 과정을 명시적으로 생성하도록 유도하는 프롬프팅 기법이다. 모델이 문제 해결 과정에서 중간 단계의 논리적 추론을 수행함으로써, 더 복잡하고 다단계의 문제를 풀 수 있도록 한다.
과정은 다음과 같다.
1. 문제 제시
2. 중간 단계 생성
3. 최종 답 도출
이와 같이 정답이 왜 나왔는지 정확한 설명을 덧붙이면 더 정확한 결과를 얻을 수 있다.

COT(Chain of Thought)
- 목적 : 모델이 생각을 단계별로 설명해서 최종 답변을 도출
- 구성방식 : 문제 -> 각 단계별 사고에 대한 설명 -> 최종 답변
- 수학문제, 논리 문제, 복잡한 질문, 정교한 코드 생성
- 예시 : 한 남자가 3개의 바구니에 각각 사과를 4개씩 넣고 있다. 총 몇개의 사과가 있나요?
- 생각1: 바구니는 3개가 있다
- 생각2: 각 바구니에는 사과가 4개씩 있다
- 생각3: 3개의 바구니 x 4개의 사과 = 총 12개의 사과가 있습니다.
- 답변:
응용 : 단계적으로 해야 하는 작업
- 단계별 데이터 분석 : 데이터 전처리, 분석, 결과 해석
- 볍률 및 금융
- 교육용 튜토리얼 생성 : 문제 풀이 과정을 각각 설명해 주고 제시어를 통해서 새로운 튜토리얼을 생성
타이타닉 데이터 단계적으로 분석하기
# 타이타닉 데이터
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()template = '''
다음 데이터를 통해 생존 여부를 판단하는 분류 모델을 만들려고 한다. 데이터를 전처리하기 위해서 다음 단계를 따른다.
step 1 : seaborn 패키지에서 타이타닉 데이터를 로드한다.
step 2 : 의미가 같은 행은 둘 중 하나만 남기고 전부 제외한다. 의미가 같은 행이란 값의 변화가 같은 행을 의미한다. 예를 들어 'survived'와 'alive'의 의미가 같으며 문자로 된 alive를 제거한다.
step 3 : 결측치를 확인해서 결측치가 있다면, 결측치가 50%가 넘는 행은 제거하고, 넘지 않으면 정수와 실수의 숫자형은 평균값으로, 그 외에는 최빈값으로 채운다.
step 4 : 수치형 데이터에 이상치가 있으면 IQR을 이용해 제거한다.
step 5 : 범주형 데이터는 one-hot-encoding을 한다.
step 6 : 학습데이터와 라벨 데이터를 분류한다. 라벨 데이터를 'survived'다.
step 7 : 데이터를 학습데이터와 테스트 데이터로 분리한다.
step 8 : 클래스 불균형이 있는지 확인확인하고 있다면 학습데이터를 SMOTE를 이용해 oversampling을 한다.
step 9 : 최종적으로 전처리한 데이터를 머신러닝 모델에 학습시킨다.
step 10 : 사용하는 모델은 현 시점에서 가장 성능이 좋은 모델을 사용한다. 부스팅 모델을 스태킹하여 사용한다.
step 11 : 모델을 평가하고 또 다른 성능이 우수한 앙상블 계열의 모델에 적용하고 평가해서 최종 모델을 선택한다. 평가 지표는 roc auc를 사용한다.
step 12 : 각 스텝별 코드를 생성하고 해당 코드들을 직접 실행할 수 있도록 각 라인에 주석을 만든다.
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-4o-mini') # gpt-3.5-turbo
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)'''
아래는 타이타닉 데이터를 전처리하고 머신러닝 모델을 학습시키는 과정을 단계별로 설명하는 코드입니다. 각 단계에 대한 주석도 추가했습니다.
```python
# Step 1: seaborn 패키지에서 타이타닉 데이터를 로드한다.
import seaborn as sns
import pandas as pd
import numpy as np
# 타이타닉 데이터 로드
titanic_data = sns.load_dataset('titanic')
# Step 2: 의미가 같은 행은 둘 중 하나만 남기고 전부 제외한다.
# 'alive' 컬럼을 'survived'로 대체하고 'alive' 컬럼 제거
if 'alive' in titanic_data.columns:
titanic_data.drop(columns=['alive'], inplace=True)
# Step 3: 결측치를 확인하고 처리한다.
# 결측치 비율 계산
missing_percentage = titanic_data.isnull().mean()
# 결측치가 50%가 넘는 열 제거
titanic_data.drop(columns=missing_percentage[missing_percentage > 0.5].index, inplace=True)
# 나머지 결측치 처리
for column in titanic_data.columns:
if titanic_data[column].isnull().sum() > 0:
if titanic_data[column].dtype in [np.int64, np.float64]: # 수치형
titanic_data[column].fillna(titanic_data[column].mean(), inplace=True)
else: # 범주형
titanic_data[column].fillna(titanic_data[column].mode()[0], inplace=True)
# Step 4: 수치형 데이터에 이상치가 있으면 IQR을 이용해 제거한다.
def remove_outliers_iqr(df):
for column in df.select_dtypes(include=[np.number]).columns:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df[column] < (Q1 - 1.5 * IQR)) | (df[column] > (Q3 + 1.5 * IQR)))]
return df
titanic_data = remove_outliers_iqr(titanic_data)
# Step 5: 범주형 데이터는 one-hot-encoding을 한다.
titanic_data = pd.get_dummies(titanic_data, drop_first=True)
# Step 6: 학습데이터와 라벨 데이터를 분류한다.
X = titanic_data.drop(columns=['survived']) # 라벨을 제외한 데이터
y = titanic_data['survived'] # 라벨 데이터
# Step 7: 데이터를 학습데이터와 테스트 데이터로 분리한다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 8: 클래스 불균형 확인 및 SMOTE를 이용해 oversampling 한다.
from imblearn.over_sampling import SMOTE
from collections import Counter
print(f'Original dataset shape: {Counter(y_train)}')
smote = SMOTE(random_state=42)
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
print(f'Resampled dataset shape: {Counter(y_train_resampled)}')
# Step 9: 최종적으로 전처리한 데이터를 머신러닝 모델에 학습시킨다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import VotingClassifier
# 개별 모델 생성
model1 = GradientBoostingClassifier(random_state=42)
model2 = RandomForestClassifier(random_state=42)
model3 = LogisticRegression(max_iter=1000, random_state=42)
# 스태킹 모델 생성
ensemble_model = VotingClassifier(estimators=[
('gb', model1),
('rf', model2),
('lr', model3)
], voting='soft')
# 모델 학습
ensemble_model.fit(X_train_resampled, y_train_resampled)
# Step 10: 모델을 평가한다.
from sklearn.metrics import roc_auc_score
y_pred_proba = ensemble_model.predict_proba(X_test)[:, 1]
roc_auc = roc_auc_score(y_test, y_pred_proba)
print(f'ROC AUC: {roc_auc}')
# Step 11: 다른 성능이 우수한 앙상블 계열의 모델에 적용하고 평가한다.
# 예를 들어, XGBoost 사용
from xgboost import XGBClassifier
xgb_model = XGBClassifier(eval_metric='auc', random_state=42)
xgb_model.fit(X_train_resampled, y_train_resampled)
y_pred_proba_xgb = xgb_model.predict_proba(X_test)[:, 1]
roc_auc_xgb = roc_auc_score(y_test, y_pred_proba_xgb)
print(f'ROC AUC for XGBoost: {roc_auc_xgb}')
# Step 12: 최종 모델 선택 및 결과 출력
if roc_auc_xgb > roc_auc:
print("최종 모델: XGBoost")
else:
print("최종 모델: Stacking Ensemble")
```
위 코드는 타이타닉 데이터셋을 전처리하고, 두 가지 모델을 학습한 후 ROC AUC 지표를 통해 성능을 평가합니다. 주석을 통해 각 단계의 목적과 기능을 설명했습니다. 각 단계를 실행하기 위해 필요한 라이브러리를 설치하고 데이터셋을 로드하는 것이 필요합니다.
'''출력 결과는 다음과 같으며 이를 실행하면,

gb, rf, lr을 soft voting 한 모델이 0.79의 성능을 보임을 확인할 수 있다. 데이터 시각화나 중복 column 제거는 더 자세한 명령이 필요하다.
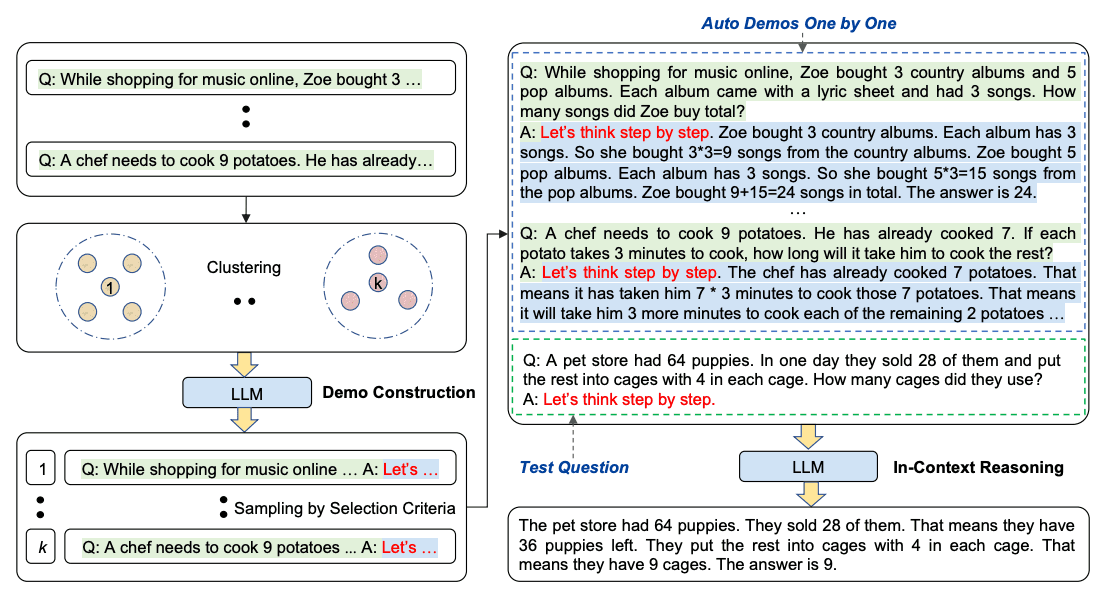
Automatic Chain-of-Thought(Auto-Cot)
- 질문클러스터 : 질문을 몇개의 클러스터로 분할
- 데모 셈플링 : 각 클러스터에서 대표 질문을 선택하고 간단한 휴리스틱을 이용해서 제로샷 을 사용해 추론 체인을 생성
- 간단한 휴리스틱 : 질문의길이(대략 60개의 토큰)와 추론 단계수(대략 5개)로 모델을 구성해서 사용
self-consistency(자기 일관성)
- 퓨샷의 cot를 통해서 여러가지 다양한 추론 경로를 샘플링하고, 여러번의 프롬프트 과정을 거쳐 가장 일관된 답을 선택하는 방법
- 모델이 단일 경로에만 의존하지 않고 여러 번의 시도를 통해 최종 답을 도출
Generated Knowledge Prompting

Integration
휴대폰 모델이
- A 한국형 a
- B 미국형 b
- 이 있을 때
- C는 동남아 모델로 a의 기본적인 것 가져옴
- 거기에 b에 있는 기능 가져올 수 있음
- merge보다 상위 개념임
# prompt를 만든다. 몇가지 묻고 답하기 형식으로
# 첫번째.. 몇가지 '지식'을 생성한다. (상식 수준에서의 지식)
# 다음의 문장들을 통해서 knowledge를 몇개 만들어줘
# input : 미국은 한국보다 크다
# knowledge : 미국의 면적은 0000 제곱 킬로미터이고, 한국의 면적은 000 제곱 킬로미터로 미국이 더 크다.
# ---
# ---
# input : 골프의 목적 중 하나는 상대발 보다 더 높은 점수를 얻기 위해 노력하는 것이다.
# Knowledge :
template = '''
Input: 그리스는 멕시코보다 크다.
Knowledge: 그리스는 약 131,957 제곱 킬로미터이고, 멕시코는 약 1,964,375 제곱 킬로미터로 멕시코가 그리스보다 1,389% 더 크다.
Input: 안경은 항상 김이 서린다.
Knowledge: 안경 렌즈에는 땀, 호흡 및 주변 습도에서 나오는 수증기가 차가운 표면에 닿아 식은 다음 작은 액체 방울로 변하여 안개처럼 보이는 막을 형성할 때 응결이 발생한다. 특히 외부 공기가 차가울 때는 호흡에 비해 렌즈가 상대적으로 차가워진다.
Input: 물고기는 생각할 수 있다.
Knowledge: 물고기는 보기보다 훨씬 더 똑똑하다. 기억력과 같은 많은 영역에서 물고기의 인지 능력은 인간이 아닌 영장류를 포함한 '고등' 척추동물과 비슷하거나 그 이상이다. 물고기의 장기 기억력은 복잡한 사회적 관계를 추적하는 데 도움이 된다.
Input: 평생 담배를 피우는 것의 일반적인 결과는 폐암에 걸릴 확률이 정상보다 높다는 것입니다.
Knowledge: 평생 동안 하루 평균 담배를 한 개비 미만으로 꾸준히 피운 사람은 비흡연자보다 폐암으로 사망할 위험이 9배 높았다. 하루에 한 개비에서 열 개비 사이의 담배를 피운 사람들은 폐암으로 사망할 위험이 비흡연자보다 거의 12배 높았다.
Input: 돌은 조약돌과 같은 크기다.
Knowledge: 조약돌은 퇴적학의 우든-웬트워스 척도에 따라 입자 크기가 4~64밀리미터인 암석 덩어리다. 조약돌은 일반적으로 과립(직경 2~4밀리미터)보다는 크고 자갈(직경 64~256밀리미터)보다는 작은 것으로 간주된다.
Input: 축구 경기에서는 다양한 전술이 있는데 반드시 이기려면 4:4:2 포멧을 사용해야 한다. 예 아니오
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-4o-mini')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)
프롬프트 체이닝
- 복잡한 작업 수행을 위해 여러개의 프롬프트(지시)를 연결하여 사용하는 방법으로 문제를 단계별로 나누어 처리할 수 있도록한다.
GPT가 말하는 주요 특징은 다음과 같다.
복잡한 작업 처리: LLM이 단일 프롬프트로 해결하기 어려운 문제를 여러 단계로 나누어 처리함으로써 성능을 개선한다.
투명성과 제어성 향상: 각 단계의 결과를 분석하고 디버깅할 수 있어, 모델의 응답을 더 쉽게 개선할 수 있다.
적용 사례: 문서 기반 질문 응답(Document QA)에서 자주 사용됩니다. 예를 들어, 첫 번째 프롬프트는 문서에서 관련된 인용구를 추출하고, 두 번째 프롬프트는 해당 인용구와 원문을 바탕으로 질문에 답변한다.
Tree of Thoughts(ToT)

CoT 기법을 확장한 방식으로 문제 해결 과정을 트리 구조로 표현하여 여러 경로를 동시에 탐색하고 최적의 해결책을 찾도록 돕는다. 탐색 알고리즘(너비 우선 탐색(BFS), 깊이 우선 탐색(DFS))을 사용하여 다양한 생각(중간 단계)을 체계적으로 평가하며, 필요할 경우 백트래킹을 통해 이전 단계로 돌아가 다른 경로를 시도한다. 이를 통해 CoT에 비해 일반화 되고 문제 해결 과정을 설명할 수 있다.
Bob is in the living room.
He walks to the kitchen, carrying a cup.
He puts a ball in the cup and carries the cup to the bedroom.
He turns the cup upside down, then walks to the garden.
He puts the cup down in the garden, then walks to the garage.
Where is the ball?
밥은 거실에 있습니다.
그는 컵을 들고 부엌으로 걸어갑니다.
그는 컵에 공을 넣고 컵을 침실로 옮깁니다.
그는 컵을 거꾸로 뒤집은 다음 정원으로 걸어갑니다.
그는 컵을 정원에 내려놓고 차고로 걸어갑니다.
공은 어디에 있나요?
다음 질문이 있을 때 정답은 처음 컵을 거꾸로 뒤집은 곳인 침실에 공이 있어야 한다.
하지만 이 복잡한 질문을 입력하면
template = '''
Bob is in the living room.
He walks to the kitchen, carrying a cup.
He puts a ball in the cup and carries the cup to the bedroom.
He turns the cup upside down, then walks to the garden.
He puts the cup down in the garden, then walks to the garage.
Where is the ball?
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)
# 출력
# The ball is in the cup in the garden.다음과 같이 다른 곳에 공이 있다고 판단한다. 이를 개선하기 위해 세명의 전문가가 서로 검증을 하는 상황이라고 가정하고, 틀리다고 판단되었을 때 떠나는 방식으로 검증을 시행하는 상황을 준다.
template = '''
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...
Bob is in the living room.
He walks to the kitchen, carrying a cup.
He puts a ball in the cup and carries the cup to the bedroom.
He turns the cup upside down, then walks to the garden.
He puts the cup down in the garden, then walks to the garage.
Where is the ball?
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)
이 출력을 다시 입력한다.
template = '''
Expert 1: Okay, first step, Bob is in the living room.
Expert 2: Second step, he walks to the kitchen, carrying a cup.
Expert 3: Third step, he puts a ball in the cup and carries the cup to the bedroom.
Expert 1: Fourth step, he turns the cup upside down.
Expert 2: Fifth step, he walks to the garden and puts the cup down.
Expert 3: Sixth step, he walks to the garage.
Expert 1: Wait a minute, I think I made a mistake. The ball would have fallen out of the cup when he turned it upside down in the bedroom. So, the ball is actually in the bedroom, not in the cup in the garden.
Where is the ball?
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)
# 출력
# The ball is in the bedroom.다음과 같이 침실에 공이 있다고 판단한다.
한국어로 하면 이 방법이 온전하게 동작하진 않는다.
대신 모델이 최신화 되면서 정확해지는 것을 알 수 있다.
template = '''
밥은 거실에 있습니다.
그는 컵을 들고 부엌으로 걸어갑니다.
그는 컵에 공을 넣고 컵을 침실로 옮깁니다.
그는 컵을 거꾸로 뒤집은 다음 정원으로 걸어갑니다.
그는 컵을 정원에 내려놓고 차고로 걸어갑니다.
공은 어디에 있나요?
'''
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
model = ChatOpenAI(model_name = 'gpt-4o-mini')
model = ChatOpenAI(model_name = 'gpt-4o')
input_prompt = prompt.format_prompt()
output = model(input_prompt)
print(output.content)gpt-3.5-turbo : 공은 컵 안에 있습니다.
gpt-4o-mini : 공은 정원에 있습니다. 밥이 컵에 공을 넣고 컵을 거꾸로 뒤집었기 때문에 공이 컵에서 빠져나와 정원에 내려놓은 상태입니다.
gpt-4o : 공은 침실에 있습니다. 이야기에 따르면, 밥은 컵에 공을 넣고 그 컵을 침실로 옮겼습니다. 그 후, 컵을 거꾸로 뒤집었기 때문에 공은 침실에 남아 있게 됩니다.
# ART : openai, naver api(검색)
# Automatic Reasoning and Tool-use(ART)
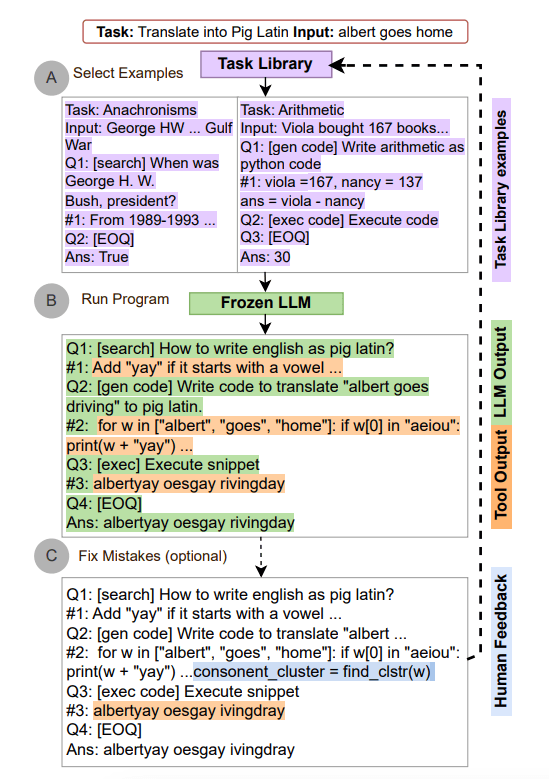
- 자동추론
- 주어진 정보와 지식을 기반으로 논리적으로 결론에 도달
- 도구사용
- 외부도구(검색엔진, 데이터베이스)를 사용
- 모델이 자체적으로 해결할 수 없는 정보가 필요할 때, 필요한 정보를 실시간으로 수집하고 처리할 수 있다.
- 예시) 질문 : "최신 인공지능 연구 동향을 알려주세요"
- AI 모델이 검색엔진을 이용해서 최신 연구 동향 관련 기사를 검색
- 결과를 분석하고 요약해서 사용자에게 제시
- 예시) 질문 :" 이 논문에서 제시하는 결과는 무엇을 의미합니까?"
- 논문 pdf 파일을 읽어서
- 내용을 분석하고 추론해서 결과를 제시
- 예시) 데이터베이스
# 웹 검색을 통한 ART
import os
import sys
import urllib.request
import json
from bs4 import BeautifulSoup
def search_web(query):
client_id = "ID"
client_secret = "SC"
encText = urllib.parse.quote(query)
url = "https://openapi.naver.com/v1/search/news.json?query=" + encText # 뉴스 결과
# url = "https://openapi.naver.com/v1/search/blog.json?query=" + encText # 블로그 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
# print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
data = json.loads(response_body.decode('utf-8'))
data = [dicdata['description'] for dicdata in data['items']]
data = [BeautifulSoup(text, 'html.parser').get_text() for text in data]
return ' '.join(data)다음과 같이 search_web이라는 함수를 정의하여 뉴스 내용을 가져온다.
# GPT를 통한 답변 생성
template = '''
뉴스기사의 내용은 다음과 같습니다.
{content}
과거의 경제현황과 현재의 우리나라의 경제 전망을 비교하면, 과거에 비해 현재는 긍정적인 부분과 부정적인 부분이 있습니다.
어떤 점긍정적이고 어떤 점이 부정적인지 설명해주세요.
관련된 정보는 뉴스 기사를 참고해 주세요
'''
prompt = ChatPromptTemplate.from_template(template)
# LLM gpt turbo
model = ChatOpenAI(model_name = 'gpt-3.5-turbo')
input_prompt = prompt.format_prompt(content = search_web('한국 경제 전망'))
output = model(input_prompt)
print(output.content)GPT가 기사 내용을 토대로 자동으로 최근 동향을 파악할 수 있게 된다.
APE(Automatic Prompt Engineer)
- LLM을 이용한 자연어 추론 해석 결과를 생성
- 이러한 결과를 수집하고 해당 결과에 대해 점수화 해서
- Hight Score인 문장들을 추출
- 해당 문장들을 이용해서 최종 메세지를 생성
- 프롬프트 자동 생성 및 최적화 프레임워크
- 프롬프트 엔지니어링 과정에서의 시행착오를 줄이고, AI가 스스로 최적의 프롬프트를 생성하고 선택할 수 있도록 돕는다
'프로그래밍 > SK AI 캠프' 카테고리의 다른 글
| 캠프55일차 - PEFT, LoRA 등 다양한 파인튜닝 기법에 대한 심화 학습 (0) | 2024.11.13 |
|---|---|
| 캠프54일차 - LLM 파인튜닝 개념과 기본 준비 (2) | 2024.11.12 |
| DACON 대회 출전 - 2024 생명연구자원 AI활용 경진대회 : 인공지능 활용 부문 (0) | 2024.11.10 |
| 윈도우 DirectX12와 WSL을 이용한 모든 GPU에서 tensorflow와 pytorch 사용하기 (1) | 2024.11.09 |
| 캠프52일차 - 프롬프트 엔지니어링 응용(랭체인, RAG(검색 증강 생성)) (1) | 2024.11.08 |


